Rob Weston

Here you will find the slides I presented at several reading groups designed to be a general intro to Bayesian Inference and linear regression. Much of the content is based on the Murpy and Bishop machine learning books which I thoroughly recommend if you want to find out more. If you have any questions or want to discuss anything please drop me an email.
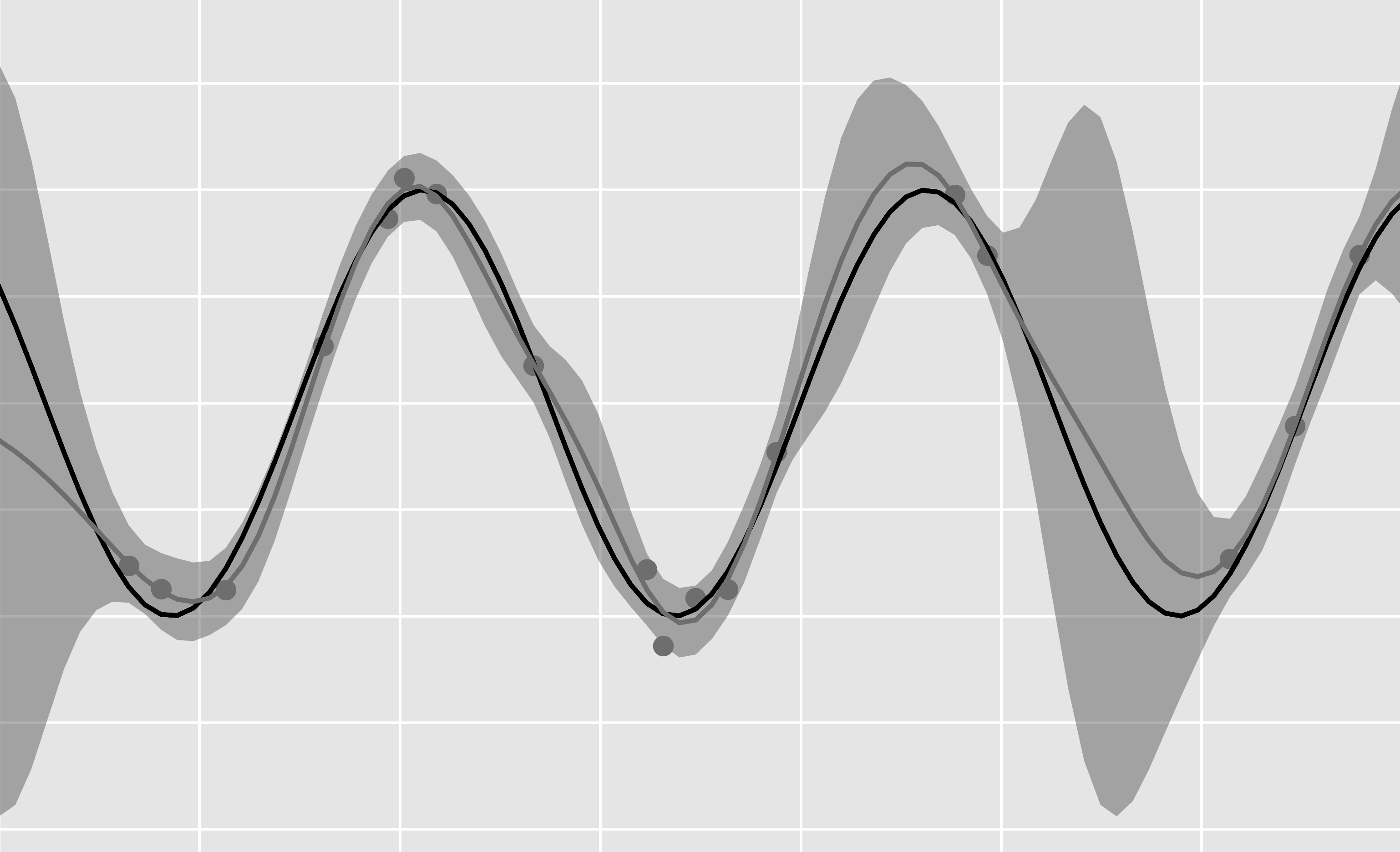
These slides were presented at the Murphy reading group at the Oxford Robotics Institute over a couple of weeks in March 2021 and were designed to cover the majority of the Bayesian statistics chapter from “Probabilistic Machine Learning: An Introduction” by Kevin Murphy.
We begin by looking at what Bayesian inference is and how it differs from a frequentist approach. Next the model is considered. Particular attention is given to the prior. We see how when using conjugate priors inference is always tractible and investigate several options for defining priors when we have litte domain knowledge at our disposal. When inference is intractible several methods exist attempting to approximate the posterior; point estimates, the laplace method, variational inference and sampling methods are all explored to this end. Finally we consider Bayesian model selection. We see how the bayesian paradigm provides us with a natural mechanism to compare the validity of different models and naturally favours the simpler explanation.
These slides were presented at the Bishop reading group with the Apllied Artificial Intelligence lab covering most of the content from “Pattern Recognition and Machine Learning” by Chris Bishop. We begin by formulating the linear regression problem. We see that maximum likelihood is a good option for estimating the underlying function from noisy data when we have large datasets available to us but for smaller $N$ our solutions significantly overfit. We explore theoretically why this is the case using the bias-variance deomposition . Introducing a norm penalty on the weights is proposed as an attempt at overcoming the limitations of Maximum likelihood for small $N$. In doing so we are able to significantly reduce the variance in our estimator at the expense of increased bias . Finally we consider linear regression from the bayesian perspective: in this case the model is naturally regularised through the process of marginalising , and all parameters can be estimated without the need for a test set, allowing us to exploit all the observations we have available.
Code for the examples given in the slides can be found here .